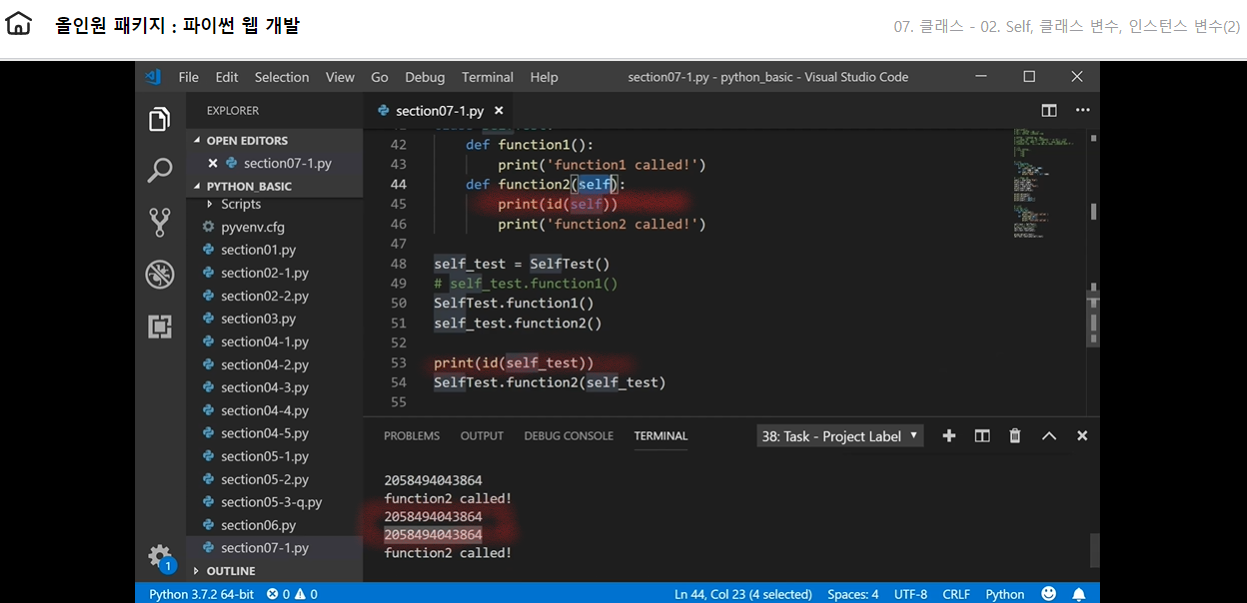
데이터베이스는 커서의 위치가 중요하다 데이터를 불러오고 난 다음에 커서는 해당 데이터 뒤에 위치하기때문이다
1 2 3 4 5 6 7 8
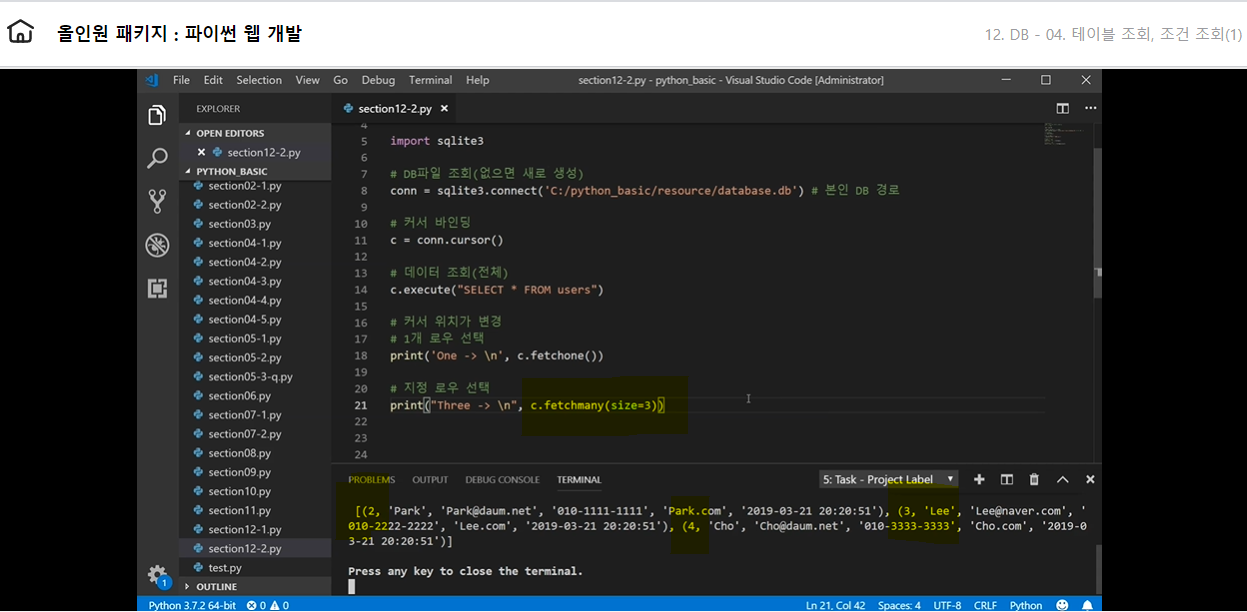
# 1개 로우 선택 print('One -> \n', c.fetchone())
# 지정 로우 선택 : size위의 숫자로 로우 갯수를 선택 print('Three -> \n', c.fetchmany(size=3))
# 전체 로우 선택 print('All -> \n', c.fetchall())
위의 명령어를 활용한 예시는 아래 이미지와 같다
터미널에서 볼 수 있듯이 1개 로우 명령어 뒤라서 커서는 1번 로우를 지난 2번로우 앞에 있다 그리고 size=3인 로우를 출력하니 2,3,4번 로우가 터미널에 출력되었음을 알 수 있다
위의 상태에서 전체 로우 print(‘All -> \n’, c.fetchall()) 명령어를 입력하면 어떻게 될까? 커서는 지금 4번로우 뒤에 위치해있기때문에 마지막 로우인 5번 데이터만 출력된다
만약 위의 상태에서 print(‘All -> \n’, c.fetchall())를 한번 더 호출하면 어떻게 될까? 커서의 위치는 마지막 로우인 5번 뒤에 있다. 따라서 호출해도 [] 빈리스트만 터미널에 출력된다.
그렇다면 처음 1번 로우를 호출하고 싶을때는 어떻게 할 수 있을까? 바로 순회하면 된다
2. 순회
순회에는 3가지방법이 있다.
순회 : 변수선언 후 for in 반복문 사용 데이터조회 명령어 c.execute(‘SELECT * FROM users’) 뒤에 실행해야 출력된다
1 2 3
rows = c.fetchall() for row in rows: print('retrieve1 >', row) # 조회 없음
순회 : 변수선언 없이 for in 반복문 바로 사용 데이터조회 명령어 c.execute(‘SELECT * FROM users’) 뒤에 실행해야 출력된다 간편하기때문에 제일많이 사용된다
1 2
for row in c.fetchall(): print('retrieve2 >', row) # 조회 없음
순회 execute(“SELECT * FROM users)는 users에 있는 전체 데이터를 조회하는 명령어이다 따라서 fetchall() 명령어와 동일한 결과값을 가진다. 데이터조회 명령어 c.execute(‘SELECT * FROM users’) 까지 포함된 명령어로 데이터조회명령어가 따로 필요없다 코드가 길어져서 가독성이 떨어지는 지는 단점이 있다. “ORDER BY id desc” 명령어를 넣어주면 역순출력이 된다
1 2
for row in c.execute("SELECT * FROM users ORDER BY id desc"): print('retrieve3 > ', row)
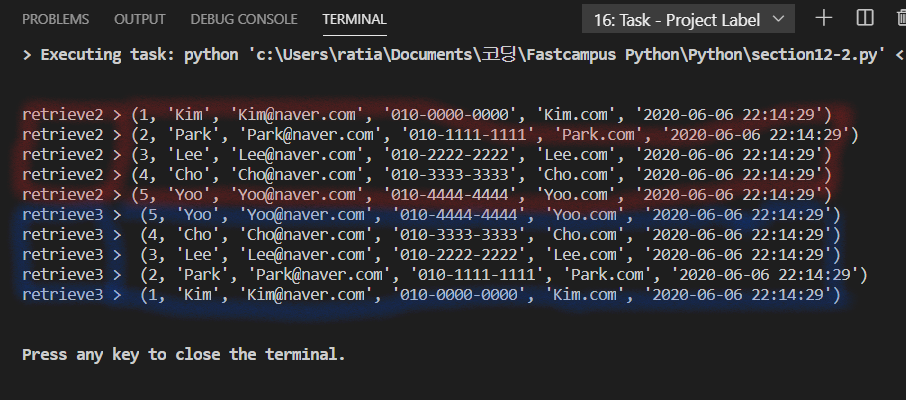
순회1번과 순회2번은 함께 쓰일수없기때문에 순회2번과 순회3번의 출력값을 아래 이미지와 같다
3. WHERE Retrieve
6가지 방법이 있고 핵심이므로 꼭 다 알고 있어야한다.
WHERE Retrieve1 튜플형태로 3번로우인 Lee를 출력 fetchone()에서 3번 로우 하나만 불러왔기때문에 그 다음 명령어로 fetchall()로 전체를 불러와도 [] 빈 리스트만 출력된다
1 2 3 4
param1 = (3,) c.execute('SELECT * FROM users WHERE id=?', param1) print('param1', c.fetchone()) print('param1', c.fetchall())
WHERE Retrieve2 튜플형태로 1번로우인 Kim을 출력 %s :문자열형, %d:정수형, %f: 실수형 fetchone()에서 1번 로우 하나만 불러왔기때문에 그 다음 명령어로 fetchall()로 전체를 불러와도 [] 빈 리스트만 출력된다
1 2 3 4
param2 = 1 c.execute("SELECT * FROM users WHERE id='%s'" % param2) print('param2', c.fetchone()) print('param2', c.fetchall())
WHERE Retrieve3 이번엔 딕셔너리형태로 1번 로우출력 id= 뒤에 :Id를 넣어준뒤 컴마찍고 딕셔너리형태로 {“Id”: 1} 첫번째로우를 호출하면 된다
1 2 3
c.execute("SELECT * FROM users WHERE id= :Id", {"Id": 1}) print('param3', c.fetchone()) print('param3', c.fetchall())
WHERE Retrieve4 리스트형태로 파라미터 2개를 받아서 1번로우와 4번로우 출력 파라미터 여러가지를 가져오려면 IN(?,?)로 넣으면 된다 이젠 한개가 아니니까 fetchone()은 쓸 수 없고 fetchall()로 출력하면 된다
1 2 3
param4 = (1, 4) c.execute('SELECT * FROM users WHERE id IN(?,?)', param4) print('param4', c.fetchall())
WHERE Retrieve5 위와 똑같은 결과값이지만 다르게 표현할 수 있다 물음표대신 정수값($d)을 넣어주면 된다 간단하기때문에 많이 사용한다
1 2
c.execute("SELECT * FROM users WHERE id In('%d','%d')" % (1, 4)) print('param5', c.fetchall())
WHERE Retrieve6 딕셔너리형태로 1번과 4번로우 출력 OR 사용
1 2
c.execute("SELECT * FROM users WHERE id= :id1 OR id= :id2", {"id1": 1, "id2": 4}) print('param6', c.fetchall())
지금까지 id를 이용했지만 username, date등을 이용해서도 출력할수있다
4. Dump 출력
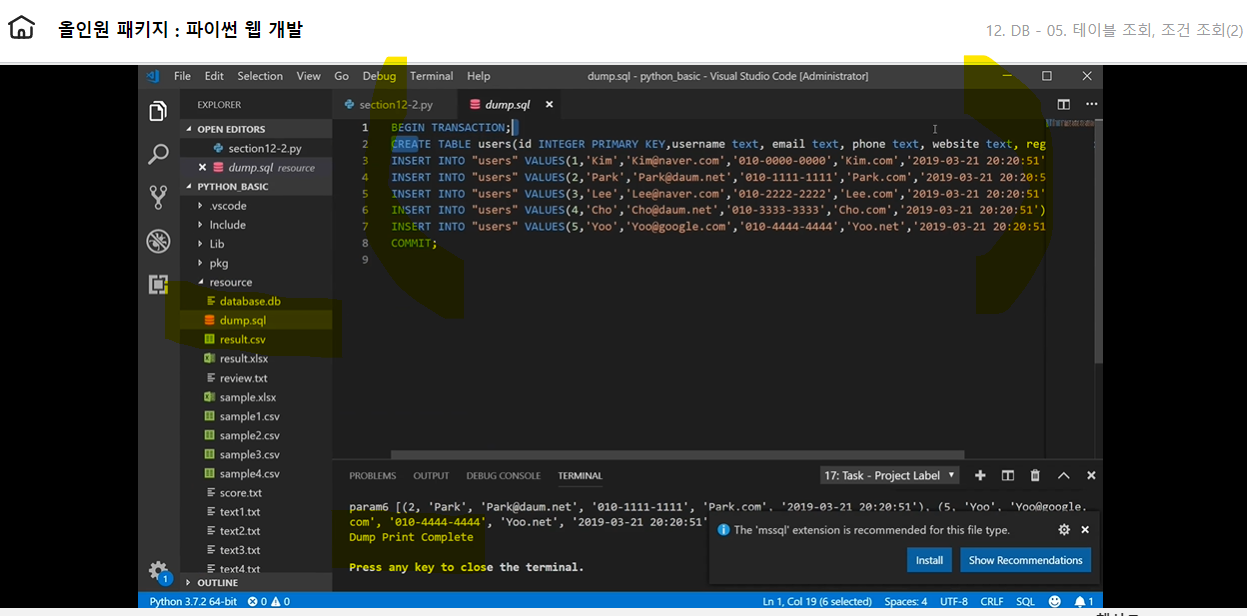
데이터베이스 백업 시 중요하다 아래 명령어를 실행하면 새로운 dump.sql이라는 파일이 형성되고 그 안에 작성한 데이터테이블이 백업된다. 이를 활용하여 sql에 붙여넣으면 다른 컴퓨터나 환경에서도 데이터사용가능하다 실무에서 흔히 ‘덤프떠와’ 라고 말한다.
with문을 사용하면 자동으로 close()를 해줘서 편리하다
with open() as f: 를 실행했으므로 f.close()가 자동으로 되었고
with conn: 을 실행했으므로 conn.close()가 자동으로 되었다
1 2 3 4 5
with conn: with open('본인이 원하는 경로/dump.sql', 'w') as f: for line in conn.iterdump(): f.write('%s\n' % line) print('Dump Print Complete.')
위의 예제를 차근차근 보자 with open(작성한 파일을 저장할장소/저장할 파일명, ‘w’(작성한다는는 의미), newline=’’) as f:
newline=’’ 이 의미는 이 부분이 없으면 한 줄씩 띄어쓰기로 for문을 순회하면서 데이터가 자동저장된다 하지만 데이터 양이 많을수록 용량도 커지고 쓸데없이 불편할 수 있다.
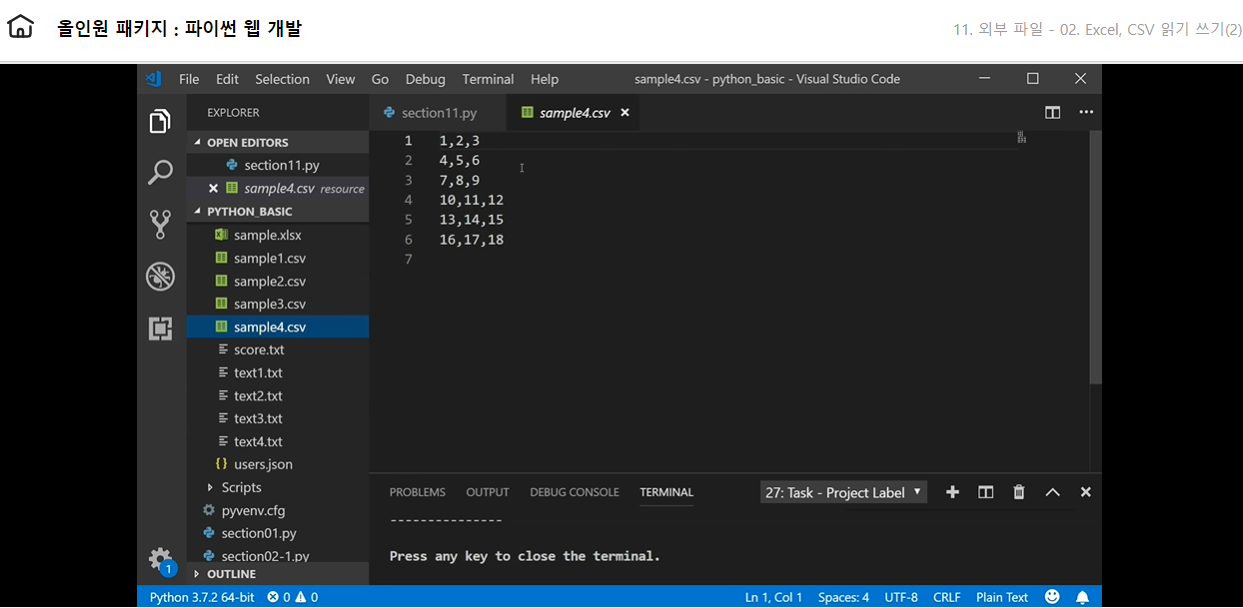
1 2 3 4 5 6 7 8 9 10 11
1,2,3
4,5,6
7,8,9,
10,11,12
13,14,15
16,17,18
그래서 ‘’빈칸을 넣어서 띄어쓰기를 없애는 것이다 newline=’’을 적용하면 아래와 같이 결과값이 출력된다
writerow()와 writerows()의 차이점
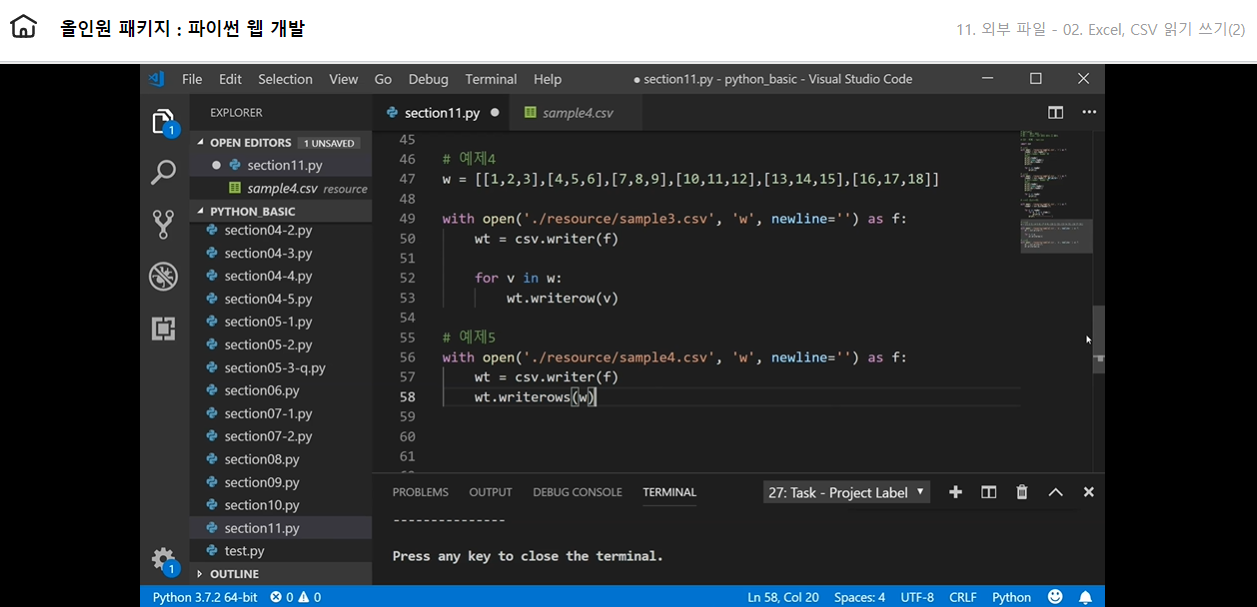
writerow()는 한줄씩 띄어쓰기하여 입력된다 -> for문을 썼기에 순회하면서 전체 내용이 출력되었다.
writerows() 한줄씩이 아닌 전체데이터가 입력된다.(for문 반복없이 한번에 입력)
한줄씩 순회하면서 입력 방법(writerow)와 한꺼번에 전체데이터를 입력하는 방법(writerows)은 각각의 장점이 있다 예시로 회원가입목록에서 1950년생이하는 빼고 데이터를 출력하고싶을때 if조건문으로 필터링을 걸어줘서 writerow이 유용하게 쓰인다
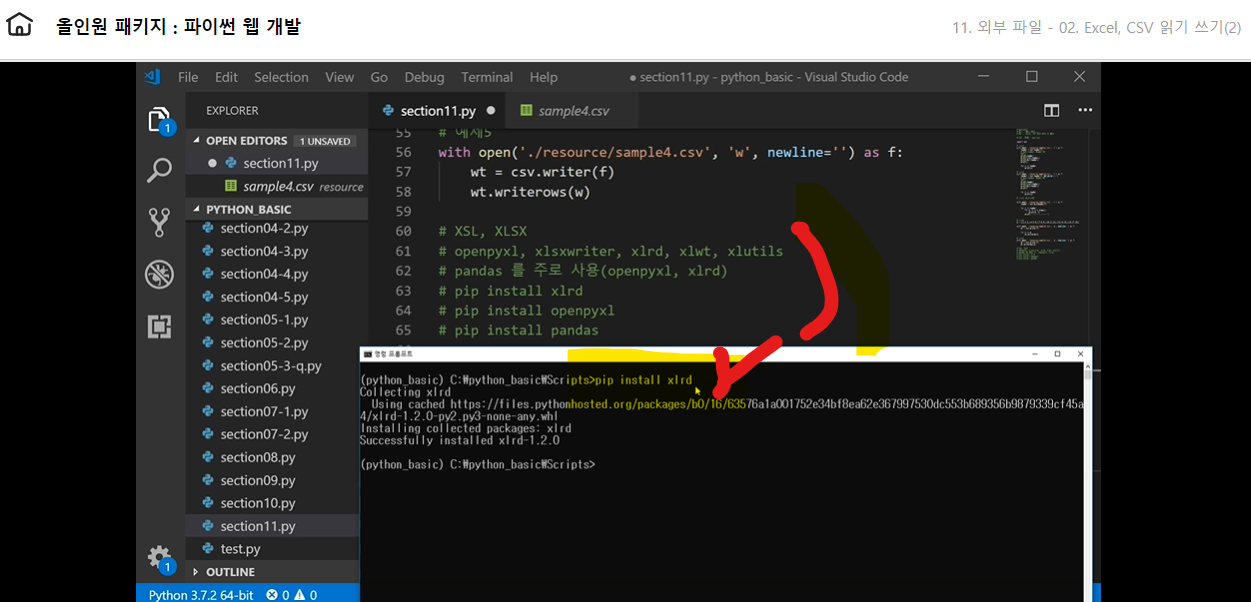
2. 엑셀 쓰기 읽기
엑셀을 처리하는 오픈소스 : openpyxl, xlsxwriter, xlrd, xlwt, xlutils 여러가지 방법이 있지만 pandas를 가장 많이 사용한다 그 이유는 pandas는 최다사용오픈소스인 openpyxl, 랭킹 1위인 xlrd를 내부적으로 만능으로 사용할 수 있기때문이다
pandas를 이용하기 위해서는 아래 3가지를 다운로드해줘야한다 1. pip install xlrd 2. pip install openpyxl 3. pip install pandas
파이썬 인강 : 데이터베이스 연동(SQLite)
SQLite는 기본적으로 설치가 되어있다. 따라서 따로 설치할 필요없이 바로 import하면 된다
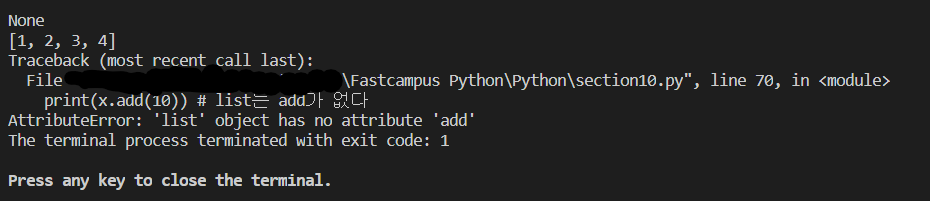
try 에러가 발생 할 가능성이 있는 코드 실행 except 에러명1: 에러가 발생하면 여기서 처리(여러 개 가능) except 에러명2: except 에러명3: else: try 블록의 에러가 없을 경우 실행 finally: 항상 실행
이를 활용한 예시
1 2 3 4 5 6 7 8
try: z = 'Kim'# 'Cho' 예외 발생 x = name.index(z) print('{} Found it! {} in name'.format(z, x + 1)) except: # 모든 에러를 처리(Exception) print('Not found it! - Occurred ValueError!') else: print('ok! else!')
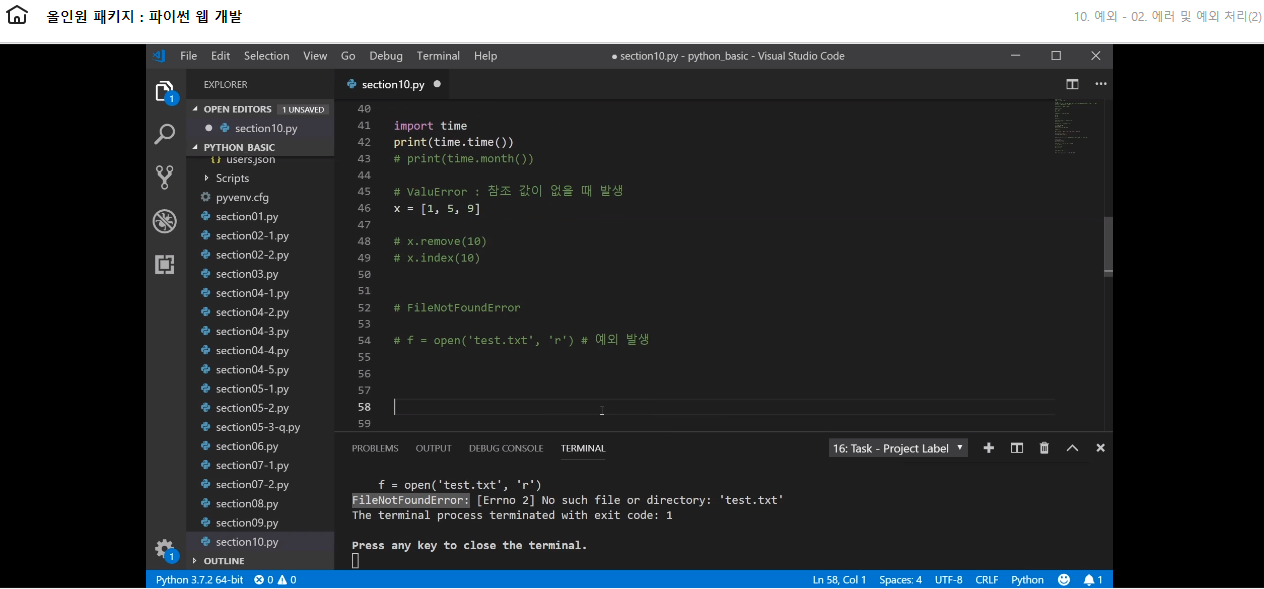
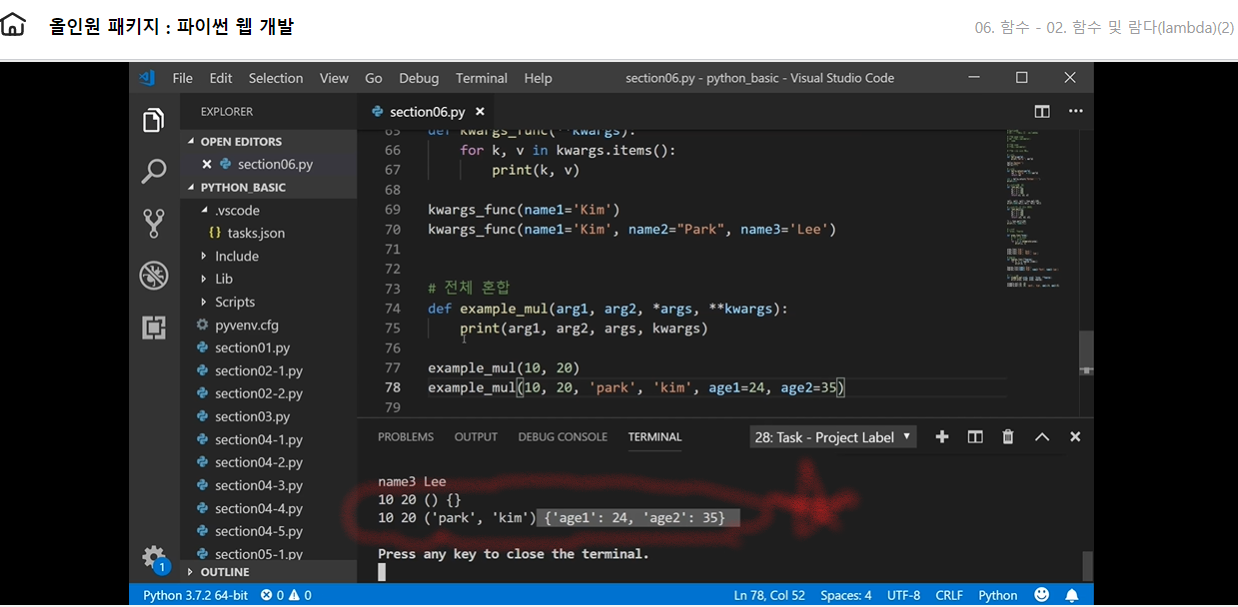
파일을 열때는 open()을 사용하고 읽어올 것이기때문에 r을 쓰면 된다 open()했으면 반드시 close 리소스 반환해줘야한다. 즉 close()로 꼭 문 닫아줘야한다. 한 번 사용한 리소스를 꼭 닫아줘야한다.
1 2 3 4 5
f = open('./resource/중요데이터.txt', 'r') contents = f.read() print(contents)
f.close()
2. with open()방법
파이썬에서는 open()해놓고 close()는 하지않아도 되는 방법이 있다 바로 with문!
1 2 3 4 5
with open('./resource/중요한데이터.txt', 'r') as f: c = f.read() print(iter(c)) #iterator함수로 변환하여 for문에서 사용가능 print(list(c)) #리스트형변환가능 print(c)
read는 전체 내용 읽어준다 ex) read(10) : 10글자 읽기
3. with문과 for문 활용
1 2 3
with open('./resource/중요한데이터.txt', 'r') as f: for c in f: print(c)
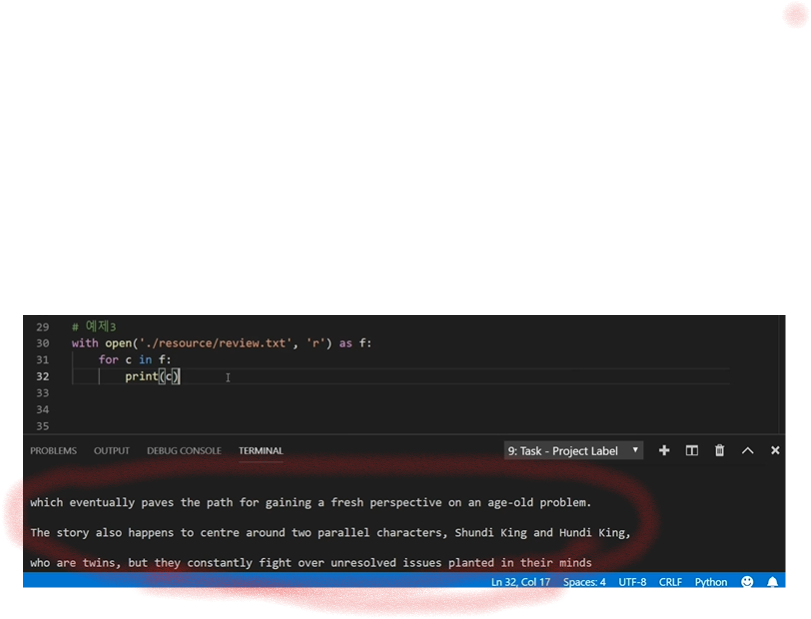
출력값을 보면 한 줄씩(line단위) 출력해준다 한줄씩 뛰어쓰기되어 나오는 것은 끝에 |n이 들어가있기때문이다 제거해주려면 어떻게 하면 될까?
1 2 3
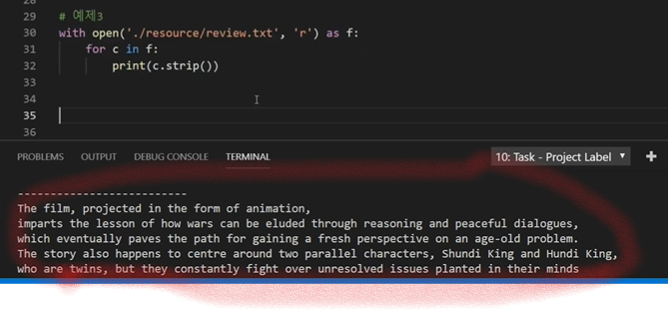
with open('./resource/중요한데이터.txt', 'r') as f: for c in f: print(c.strip())
|n을 strip()으로 제거해주면 가독성 좋게 출력된다 위의 출력이미지와 아래의 출력이미지를 보면 가독성이 좋아진 것을 알 수 있다
4. read VS readline VS readline(문자수) VS readlines
read : 처음글자부터 끝까지 전체를 다 읽기. read()가 끝나고 나면 커서가 맨 마지막 글자에 있기때문에 한번 출력 후 read()를 또 출력하면 빈 내용이 출력된다
readline : 한 줄씩 읽기
readline(문자수) : 문자수 읽기
readlines : 전체 읽은 후 라인 단위 리스트 저장
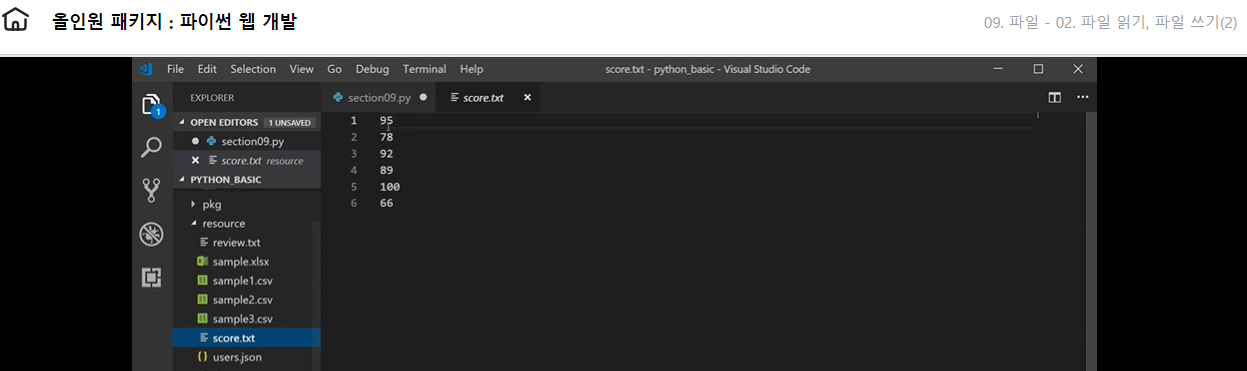
응용한 예시를 함께보자 아래 이미지파일과 같은 score.txt파일이 있고 안의 내용의 평균을 for line in으로 구해보자
1 2 3 4 5 6 7 8 9 10 11
with open('./resource/score.txt', 'r') as f: score = [] for line in f: score.append(int(line)) print(score) print('Average : {:6.3f}'.format(sum(score) / len(score))) #{6자리고 소수셋째자리까지라는 의미}
# 출력값 [95, 78, 92, 89, 100, 66] Average : 86.7
5. 파일 쓰기
빌트인패키지인 random을 이용해서 파일을 써보자 로또번호와 비슷하게 6개 랜덤번호를 출력하는 예제이다.
1 2 3 4 5 6 7
from random import randint #랜덤파일로부터 randint함수를 가져와라는 뜻
with open('test2.txt', 'w') as f: for cnt in range(6): # range(6)은 0~5까지임. f.write(str(randint(1, 50))) # 1부터50까지 f.write('\n')
writelines : 리스트 -> 파일로 저장
1 2 3
with open('test3.txt', 'w') as f: list = ['Kim\n', 'Park\n', 'Lee\n'] f.writelines(list)
print로 바로 저장하는 예제이다
1 2 3
with open('./resource/test3.txt', 'w') as f: print('Test Contents!', file=f) print('Test Contents!!', file=f)
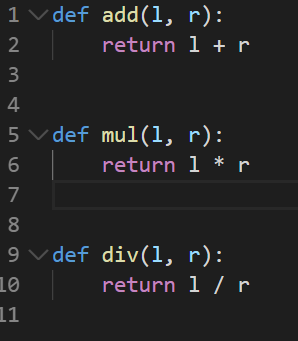
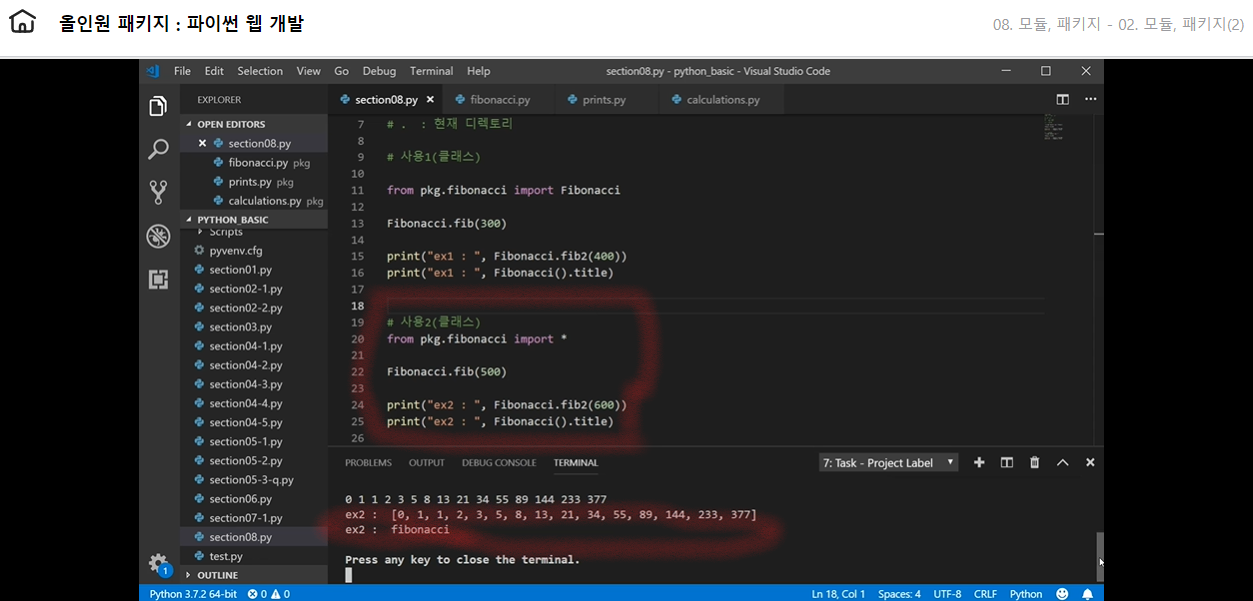
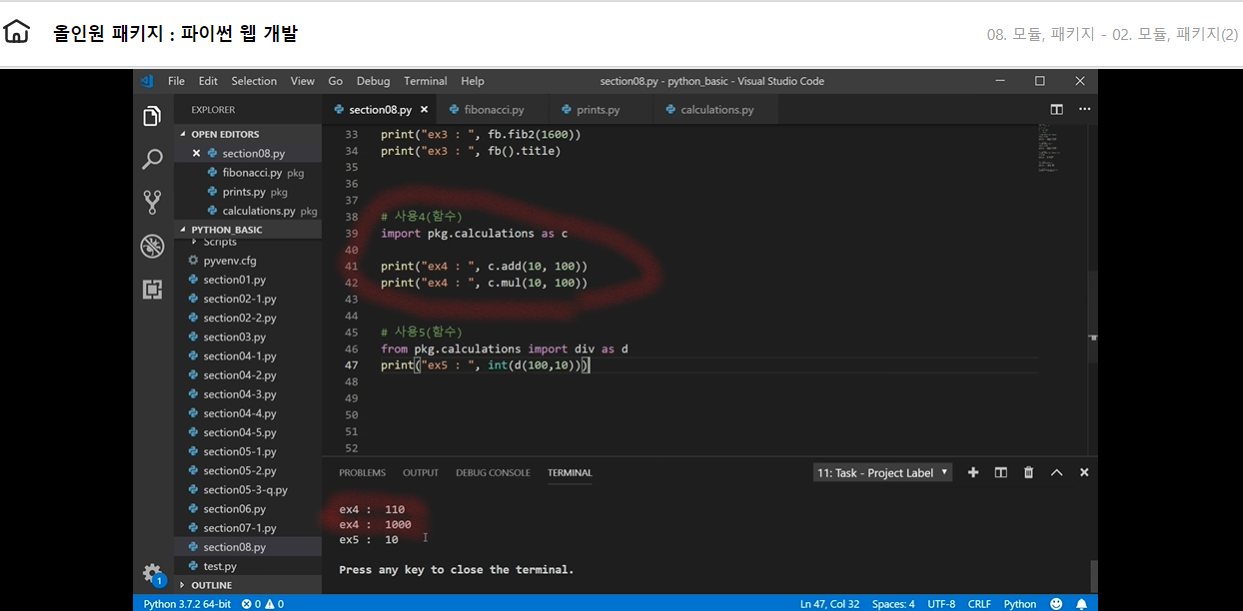
from + import + as 조합 권장하는 방법으로 모듈의 많은 함수들 중에서 필요한 함수만 가져와서 쓸수있다 어떠한 언어를 다루던 리소스를 낭비하지 않도록 명확히 코딩하는 것이 좋다
1 2 3 4 5 6
from pkg.calculations import div as d
print("ex5 : ", int(d(100,10)))
# 출력값은 ex5 : 10
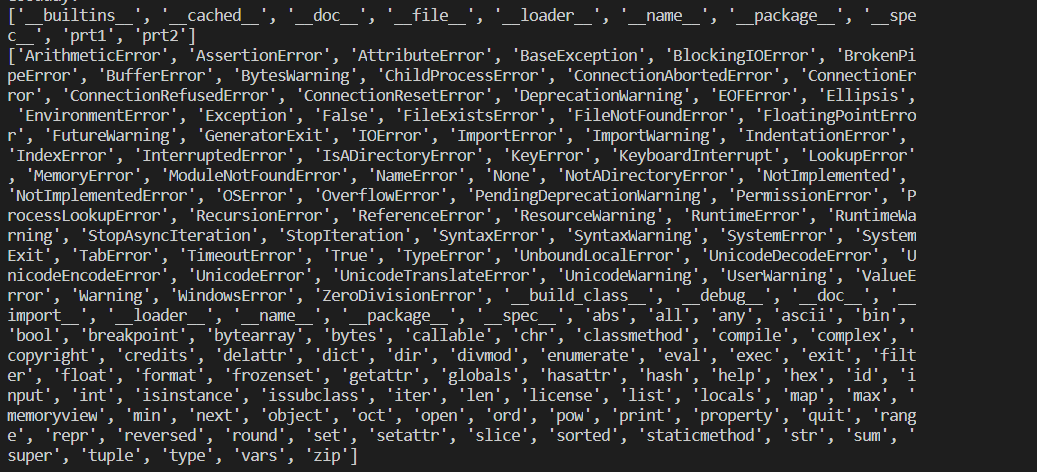
3. builtins(빌트인)
1 2 3
import builtins
print(dir(builtins))
출력값이 너무 길어서 이미지파일로 준비했다
우리가 빌트인인지 모르고 사용했던 list함수, type함수등이 들어가 있는 것을 확인할 수 있다
4. __init__.py의 필요성
용도 : 해당 디렉토리가 패키지임을 선언할 때 사용한다. Python 2.x대를 사용하고 있다면 __init__.py가 필수이다 Python3.x : 파일이 없어도 패키지 인식하지만 3.x보다 하위 버전 호환 위해서 생성하는 것이 안전
5. 단위테스트
독립적으로 만든 파일이 독립적으로 잘 실행되는지는 확인하기 위해서 아래 if name문을 써준다 아래 형태로 쓰도록 딱 정해놓았다. 만든함수()부분에 만들었던 함수들을 넣어 독립적으로 실행되는지 체크할 수 있다 if문이기때문에 import으로 가져온 파일에서는 출력이 안된다 GOOD!
1 2 3 4 5
# 단위 실행(독립적으로 파일 실행) if __name__ == "__main__": print("This is", dir()) 만든함수() 만든함수()
*args (아스타) arguments의 약자로 가변인자(인자의 갯수가 변할 수 있음)를 뜻한다 다양한 매개변수를 받아서 함수의 흐름이 바뀌게한다 매개변수를 하나를 넣든 세개를 넣든 튜플의 형태로 출력해준다 기본적으로 *args라고 적지만 이 매개변수명은 자유롭게 변경 가능하다 enumerate는 순회라는 의미로 index를 넣어서 나타낼 수 있다. 꼭 알아두자
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
defargs_func(*args):# 매개변수명 자유롭게 변경 가능 for i, v in enumerate(args): print(v, i)






![[패스트캠퍼스python] 상속, 다중상속](/img/python06013.png)







![[네트워크] Socket(소켓) vs Websocket(웹소켓) 차이점](/img/240111OSI7LayerAndTCPIP.jpg)