[패스트캠퍼스python] Web 기초 (클라이언트 VS 서버, 웹프로그래밍, HTTP, 크롬 개발자도구)
파이썬 인강 : Web 기초 (클라이언트 VS 서버, 웹프로그래밍, HTTP, 크롬 개발자도구)
15회차까지는 파이썬 기초를 배웠다.
이번에는 web기초를 후루룩 배워보자
자주 접했지만 아직 암기까진 못한 웹기초!
이번엔 기초를 탄탄히 쌓아서 다시 보는 일이 없었으면 좋겠다 ㅋㅋㅋㅋㅋ

1. 클라이언트 (client) VS 서버 (server)
클라이언트와 서버, 이 둘은 절대적인 개념이 아니라 상대적인 개념이다.
웹 브라우저가 설치된 컴퓨터에서 다른 컴퓨터에 요청을 하는 클라이언트이면서도 또다른 웹 브라우저에 요청을 받는 서버컴퓨터일 수 도 있다.
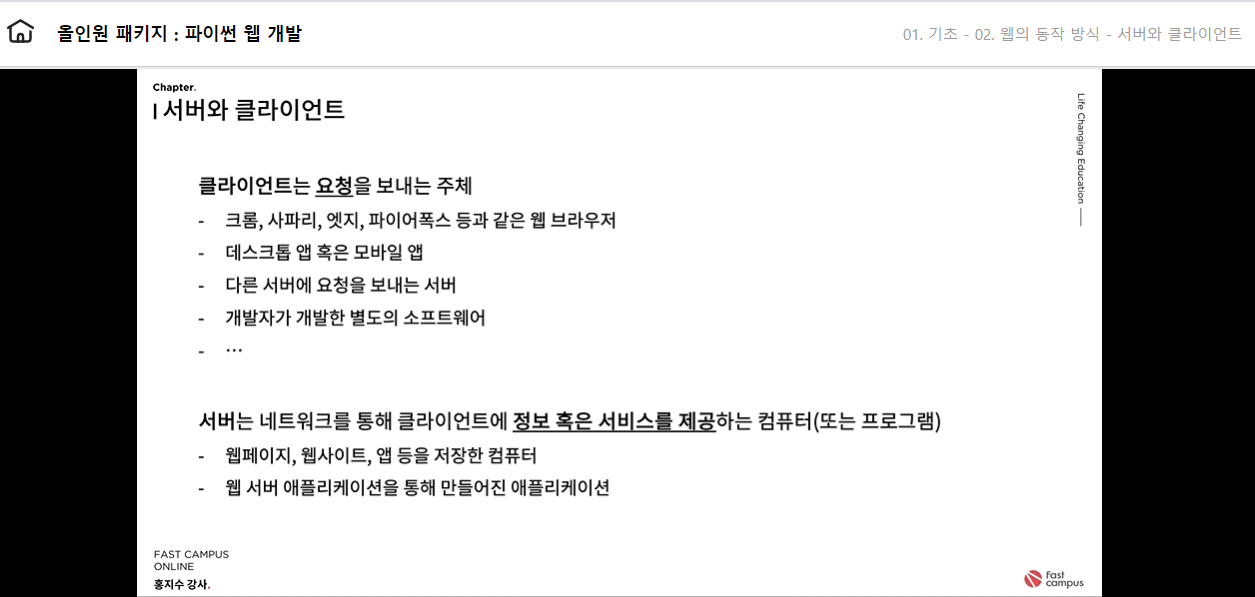
- 클라이언트 : 요청을 보내는 주체
- 크롬, 사파리, 엣지 파이어폭스 등과 같은 웹브라우저
- 데스크톱 앱 혹은 모바일 앱
- 다른 서버에 요청을 보내는 서버
- 개발자가 개발한 별도의 소프트웨어
- 등등등
- 서버 : 네트워크를 통해 클라이언트에 정보 혹은 제공하는 프로그램 또는 컴퓨터
- 웹 페이지, 웹 사이트, 앱 등을 저장한 컴퓨터
- 웹 서버 애플리케이션을 통해 만들어진 애플리케이션
- 등등등
이번 강의에서 배울 파이썬기반의 프레임워크인 Flask와 Django로 만들어진 어플리케이션이 서버역할을 수행할 수 도 있다.
이처럼 요즘에는 웹 프레임워크를 이용하여 웹 서버를 개발한다.
2. 웹프로그래밍 (Web Programming)
웹 프로그래밍이란 HTTP로 통신하는 클라이언트와 서버를 개발하는 것을 말한다.
클라이언트와 서버는 앞에서 배웠는데 HTTP 프로토콜은 무엇일까?
3. HTTP (HyperText Transfer Protocol)
HTTP(HyperText Transfer Protocol)란 웹서버와 클라이언트 즉, 브라우저가 인터넷에서 서로 테이터를 주고 받기 위한 약속체계이다.
그럼 실질적으로 HTTP 요청과 HTTP 응답에 대해 자세히 알아보자

- HTTP 요청
- 매서드 Method
- 실제 서버가 수행해야하는 동작들이다.
- get : 정보를 가져오기
- post : 정보를 올리기
- delete : 삭제하기
- 실제 서버가 수행해야하는 동작들이다.
- URL주소
- 헤더 Header
- 브라우저 정보
- 언어
- 등등 여러정보가 포함된다.
- 본문 body
- 있을 수도 있고 없을 수도 있다.
- 페이스북으로 예를 들자면, 아이디나 패스워드 입력창이나 새글내용등이 본문에 해당된다.
- HTTP 응답
상태코드
- 요청의 성공여부가 가장 먼저 표시된다.
- 예시
- 200은 성공했다는 의미이다.
- 404 Not Found …는 실패했다는 의미이다.
헤더 Header
본문 body
- HTML(Hypertext Markup Language)코드등의 파일
- 에러가 났다면 생략될 수 있다.
4. 크롬 개발자도구 (chrome developer tools)
위의 이미지에서 볼수있듯이 크롬 개발자도구로 많은 것들을 할 수 있다
Elements
엘리먼트탭에서는 각 요소에 대해 알수있으며, 속성값을 다르게 입력하는 등 간단하게 일시수정도 가능하다.
일시수정이라서 영영 저장되거나 보존되는 것이 아닌 그냥 임시적으로 수정가능하다.Console
콘솔탭에서는 자바스크립트 (javascript)를 다룰 수 있다.Sources
소스탭에서는 현재 웹페이지가 가지는 모든 소스코드들중 공개된 코드들을 마음껏 볼 수 있다.Network
네트워크탭은 페이지를 로딩하는데 필요한 네트워크작업에 대한 결과를 시간순으로 표시해준다.
이를 통해서 웹서버와 주고받는 실제 데이터 모습을 볼 수 있다.
- 위의 이미지 오른쪽 하단부분에 Method를 확인 할수있다. 위에서 배웠던 get과 post매서드를 확인할 수 있다.
- 위에서 status를 확인할 수 있다 200으로 성공이 되었음을 의미한다.
- type에서도 해당 웹사이트가 불러온 데이터의 타입이 gif 이미지파일인지, script파일인지 아니면 text/html파일인지 등등을 확인할 수 있다.






![[패스트캠퍼스python] 상속, 다중상속](/img/python06013.png)





![[OS/WINDOW]배포후 서버재시작에 batch와 윈도우 스케줄러 활용하기](https://cdn.pixabay.com/photo/2012/03/04/00/50/board-22098_960_720.jpg)
![[블로그]헥소테마에서 댓글기능 facebook에서 utterances로 변경하기](https://miro.medium.com/max/1600/1*aOv6h3h_v9PQWa03zGACnw.png)