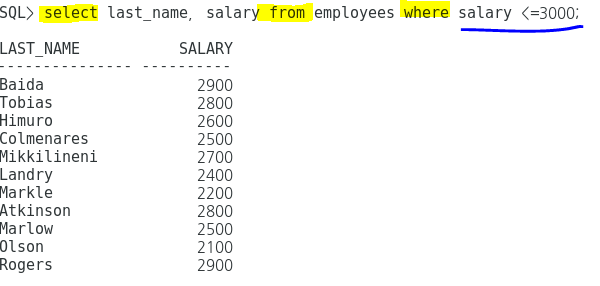
반복문 : for 반복문의 기본식은 아래와 같다
1 2 3 for (초기식; 조건식; 증감식){ 반복문장 }
if나 for 문은 중괄호{} 없이도 반복이 된다. 하지만 세미콜론;전까지의 한줄만 반복한다
반복문의 순서
초기식
조건식
반복문장
증감식
조건식
반복문장
증감식
위의 3가지 반복
조건식 (조건이 충족된 경우)
반복문 종료
개발자 도구를 이용하여 간단한 디버깅을 할 수 있다
Sources탭에서 디버깅원하는 소스코드파일을 클릭 후 디버깅원한느 코드의 줄번호 앞부분 클릭 -> 빨간 점으로 표시됨
Block기준으로 변수의 값이 변화 확인 가능
4번에 보이는 회색점을 클릭하면 빨간색점으로 변경됨 -> 점마다 break point가 걸려 순서를 세세하게 볼 수 있음
옅은 파란 블럭이 이동하면서 코드 실행순서를 가시적으롭 보여줌
디버깅이 끝났으면 꼭 줄번호 옆의 빨간색점을 체크해제해줘야 디버깅 모드가 중단된다
기본 반복문암기 기본적인 반복문은 암기해서 바로바로 쓰는 것이 좋다
몇씩 증감하는 반복문 1~10까지 짝수만 출력하는 반복문을 생각하자마자 나는 if조건이 들어간 for문을 생각했다
1 2 3 4 5 for (let i=0 ; i<=10 ; i++){ if (i%2 !==0 ){ document .write(' ' +i); } }
강사님이 보더니만 결과값은 일치하지만 효율을 위해서 간단한건 조건문이 안들어간 반복문으로 나타내는 것이 좋다고했다.
음 그렇군! 오케이 접수!
1 2 3 for (let i=1 ; i<=10 ; i+=2 ){ document .write(' ' +i) }
for문안의 증감식을 변경하여 몇씩 증감한다고 하면 주로 위의 코드를 이용하면 된다!
누적합 정말 많이봐서 이제 익숙하다
1 2 3 4 5 let sum = 0 for (let i=0 ; i<=10 ; i++){ sum+=i } document .write(sum)
카운트 횟수를 셀 때 자주 사용한다
1 2 3 4 5 let count = 0 ;for (let i=1 ; i<=10 ; i++){ count+=1 ; } document .write(count);
for문과 if문의 자리바꿈에 따른 변화 사용자가 입력하는 숫자의 구구단을 출력하는 예시를 보자
1 2 3 4 5 6 7 8 9 10 let num = prompt('구구단 숫자를 입력하세요' ); for (let i=1 ; i<=9 ; i++){ if (num > 0 ){ document .write(num + ' * ' + i +' = ' + (num*i)+ '<br>' ) }else { alert('잘못입력했습니다 1~9까지 숫자중에 입력하세요' ) break ; } }
위에서 num을 0이하로 입력했다면 alert창 띄우고 다시 숫자를 입력하도록 하게 하고싶었다. 근데 이 로직으로는 감이 잡히지않았다.
1 2 3 4 5 6 7 8 9 10 let num = prompt('구구단 숫자를 입력하세요' ); if (num>0 ){ for (let i=0 ; i<=9 ; i++){ document .write(num + ' * ' + i +' = ' + (num*i)+ '<br>' ) } }else { alert('잘못입력했습니다 1~9까지 숫자중에 입력하세요' ) location.reload(); }
반복문 : While 반복문 while의 기본식은 아래와 같다
1 2 3 4 5 초기식; while (조건식){ 반복할문장; 증감식; }
증감식을 꼭
전위연산 VS 후위연산 전위연산과 후위연산은 잘 비교해야한다
전위연산1 2 3 4 let i=1 ;while (i++ <=4 ){ document .write(i+", " ) }
i = 1 -> 조건식 : 참 -> i++ -> write : 2
i = 2 -> 조건식 : 참 -> i++ -> write : 3
i = 3 -> 조건식 : 참 -> i++ -> write : 4
i = 4 -> 조건식 : 참 -> i++ -> write : 5
i = 5 -> 조건식 : 거짓 -> 종료
후위연산1 2 3 4 let i=1 ;while (++i <=4 ){ document .write(i+", " ) }
i = 1 -> ++1 라서 2 -> 조건식 : 참 -> write : 2
i = 2 -> ++1 라서 3 -> 조건식 : 참 -> write : 3
i = 3 -> ++1 라서 4 -> 조건식 : 참 -> write : 4
i = 4 -> ++1 라서 5 -> 조건식 : 거짓 -> 종료
do-while()문 조건 비교하기 전에 한 번 실행후 조건을 비교한다
기본형태이다
1 2 3 4 5 초기식; do { 반복문장; 증감식; }while (조건식)
초기식과 증감식 없더라도 확인가능하다
1 2 3 4 5 6 let i = 1 ;do { document .write(i+" " ); i++; }while (i<=10 );
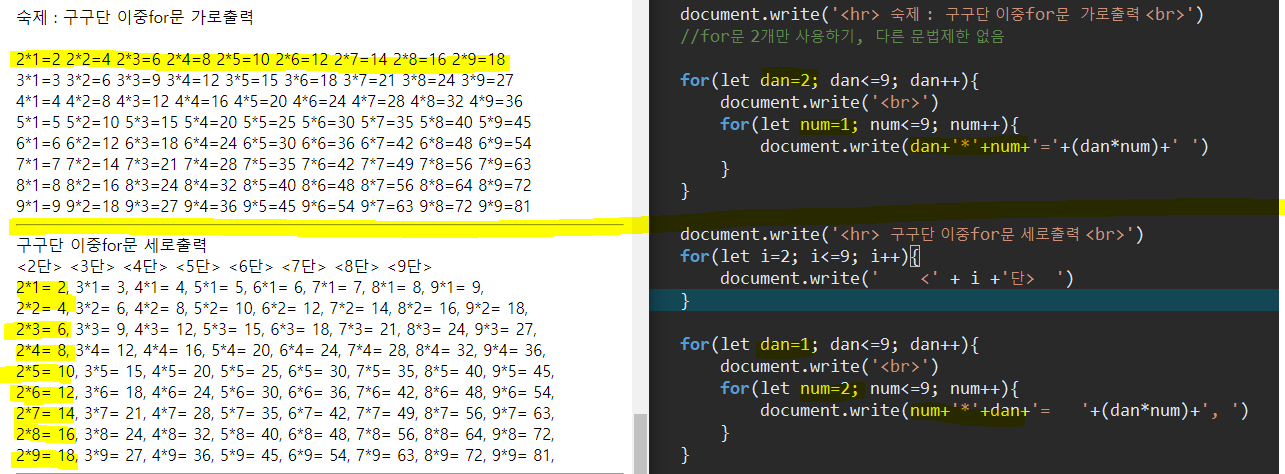
예시: 구구단 세로로 나타내기 구구단을 가로가 아닌 세로로 나타내보자
구구단 가로출력1 2 3 4 5 6 for (let dan=2 ; dan<=9 ; dan++){ document .write('<br>' ) for (let num=1 ; num<=9 ; num++){ document .write(dan+'*' +num+'=' +(dan*num)+' ' ) } }
가로출력의 첫번째 반복은 dan이 고정이고 num이 1부터 9까지 변화한다
이 두 사실을 가지고 변수와 숫자를 적절히 바꾸어주면 된다
구구단 세로출력
for문과 이중for문으로 만든 코드이다
1 2 3 4 5 6 7 8 9 10 for (let i=2 ; i<=9 ; i++){ document .write(' <' + i +'단> ' ) } for (let dan=1 ; dan<=9 ; dan++){ document .write('<br>' ) for (let num=2 ; num<=9 ; num++){ document .write(num+'*' +dan+'= ' +(dan*num)+', ' ) } }
아래 이미지파일을 보면 왼쪽이 출력값이고 오른쪽이 소스코드이다
이중for문 하나로 만들 순 없을까?
당연히 만들수있다! if를 이용하면 된다!
1 2 3 4 5 6 7 8 9 10 11 for (let num=0 ; num<=9 ; num++){ for (let dan=2 ; dan<=9 ; dan++){ if (num == 0 ){ document.write(' <' + dan +'단> ' ) }else { document.write(dan+'*' +num+'= ' +(dan*num)+', ' ) } } document.write('<br>' ) }
반복문으로 테이블만들기 테이블만드는 방법도 다양하다
테이블은 행x열(4x3)이고 각 칸안에는 1~12까지의 수를 넣은 테이블을 만들어보자
이중 for문 사용
1 2 3 4 5 6 7 8 9 10 11 12 13 let tageOpen="<table border='1'>" let tageClose="</table>" document .write(tageOpen)let count = 0 ;for (let tr=1 ; tr<=4 ; tr++){ document .write('<tr>' ) for (let td=1 ; td<=3 ; td++){ document .write('<td>' + (count+=1 ) + "</td>" ) } document .write('</tr>' ) } document .write(tageClose)
tag로 테이블만들기
1 2 3 4 5 6 7 8 9 10 11 12 13 let tageOpen="<table border='1'>" let tageClose="</table>" let trtdtag;let count1 = 0 ; for (let i=1 ; i<=4 ; i++){ trtdtag += "<tr>" ; trtdtag += "<td>" + (count1+=1 ) + "</td>" ; trtdtag += "<td>" + (count1+=1 ) + "</td>" ; trtdtag += "<td>" + (count1+=1 ) + "</td>" ; trtdtag += "</tr>" } document .write(tageOpen + trtdtag + tageClose )
아래와 동일 테이블이 만들어진다.
1
2
3
4
5
6
7
8
9
10
11
12
![[JS] 반복문 for 순서 자세히, 개발자 도구로 디버깅, 기본 반복문암기, for문과 if문의 자리바꿈에 따른 변화, 반복문의 전위연산 VS 후위연산, do while문](/img/200609jspi0.PNG)






![[OS/WINDOW]배포후 서버재시작에 batch와 윈도우 스케줄러 활용하기](https://cdn.pixabay.com/photo/2012/03/04/00/50/board-22098_960_720.jpg)
![[블로그]헥소테마에서 댓글기능 facebook에서 utterances로 변경하기](https://miro.medium.com/max/1600/1*aOv6h3h_v9PQWa03zGACnw.png)