조건문과 반복문 중간 점검 퀴즈를 하였다 데이터타입 중간 점검 퀴즈와는 다르게 조금 어려웠다.
여러 문제를 풀었지만 내가 모르는 문제해결방법 위주로 정리해보았다 이번 중간 퀴즈도 역시 유익했다.
1. 아래 딕셔너리에서 ‘가을’에 해당하는 과일을 출력하세요.
동일한 접근 방법이지만 keys()를 가져올 지 items()를 가져올 지 선택할수있다
첫번째 방법 : for와 if문 사용
1 2 3 4 5
q1 = {"봄": "딸기", "여름": "토마토", "가을": "사과"}
for k in q1.keys(): if k == '가을': print(q1[k])
두번째 방법 : keys()말고 items()가져오기
1 2 3
for k, v in q1.items(): if k == '가을': print(v)
첫번째, 두번째 출력값은
1 2
사과 사과
2. 다음 세 개의 숫자 중 가장 큰수를 출력하세요.(if문 사용) : 12, 6, 18
나는 아래와 같이 풀었다. 쉽게쉽게~!
1 2 3 4 5 6 7 8 9 10 11 12 13 14
a = 12 b = 6 c = 18
if a > b: if a > c: print(a) else: print(c) else: print(b) # 출력값은 18
위는 내가 푼 코드이고 아래는 강사가 푼 코드이다. 변수선언이나 코드길이도 훨씬 효율적여보인다. 여러 방법으로 푸는 방법을 익히고 그리고 여러 방법으로 풀어보려는 자세가 중요하다.
1 2 3 4 5 6 7 8
a, b, c = 12, 6, 18 best = a
if b > a: best = b if c < b: best = c print('best : ', best)
두 방법 다 꼭 기억해야겠다.
3. s에서 7자리 숫자를 사용해서 남자, 여자를 판별하세요. (1,3 : 남자, 2,4 : 여자)
처음에 어떻게 풀지 막막했다. 결국 겅의를 보게 되었고 결과는 허무했다. 이렇게 간단한거였는데 풀지도 못하다니 수학적 사고를 길러야겠다고 생각이 들었다
1 2 3 4 5 6 7 8 9
s = '021022-4473837'
if int(s[7]) % 2 == 0: print('여자') else: print('남자')
# 출력값은 여자
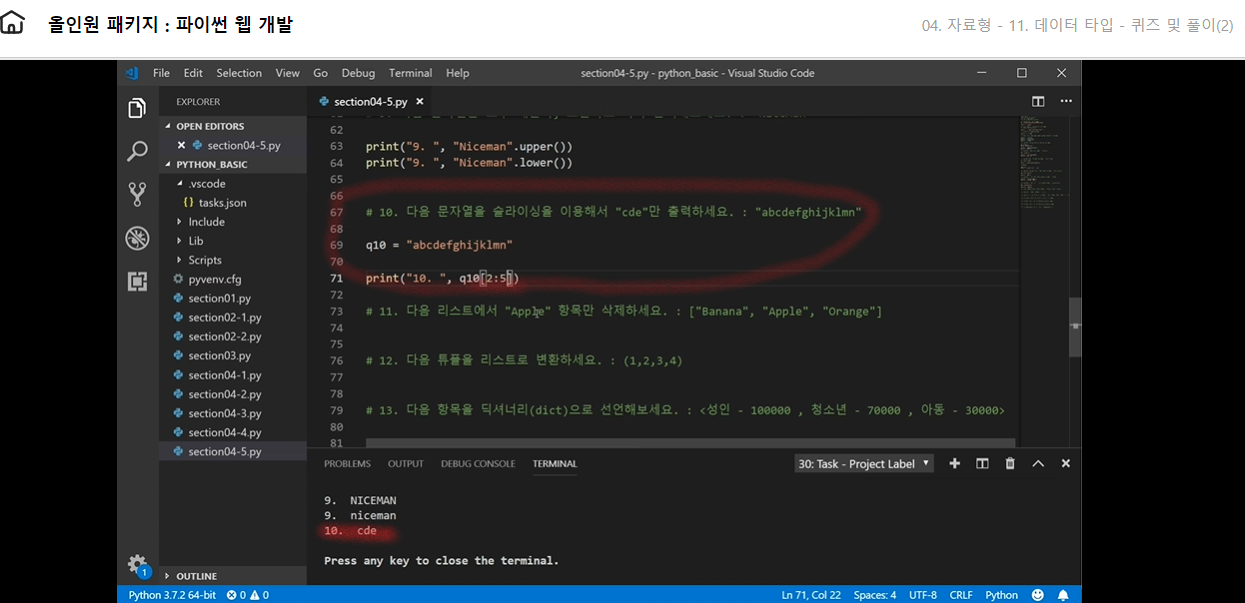
4. 다음 리스트 중에서 ‘아’ 글자를 제외하고 출력하세요.
여기서 continue 를 쓸 생각을 하지못했다. 슬라이싱 처리하려고 했는데 잘 안되서 막막하던 차에 강의에서 continue쓰고 묵혔던 답답함이 쏴악 해소되었다. 이제 컨디뉴 절대 안 잊어버릴것같다
1 2 3 4 5 6 7 8 9 10 11
q3 = ["지", "컨", "아", "세", "요"]
for v in q3: if v == '아': continue else: print(v, end='') print()
# 출력값은 지컨세요
5. 아래 리스트 항목 중에서 5글자 이상의 단어만 출력하세요.
이건 보자마자 길이함수를 써야겠다는 확신이 들었다 js를 할때 길이를 항상 length()로 사용해서 무의식적으로 length()적었다가 에러가 떴다 아차차 하고 바로 len()로 바꿨다 비슷하지만 조금씩 다른 함수들이 있어서 가끔 혼동스럽다 헷갈리지 않도록 더 빡세게 암기해야겠다.
1 2 3 4 5 6 7 8 9
q4 = ["nice", "study", "python", "anaconda", "!"]
for v in q4: if len(v) >= 5: print(v, end=' ') print()
# 출력값은 study python anaconda
6. 아래 리스트 항목 중에서 소문자만 출력하세요.
나는 당연히 islower()함수만 썼는데 강의에서 continue를 써서 깜짝 놀랬다. 이런 부분때문에 혼자 공부하는 것보다 강의나 여럿이 공부하는 것이 좋은 것같다 어서 실력을 키워 모각코나 스터디그룹을 만들고 싶다
1 2 3 4 5 6
q5 = ["A", "b", "c", "D", "e", "F", "G", "h"]
for v in q5: if v.islower(): print(v, end=' ') print()
또는 continue를 써서 풀수도 있다
1 2 3 4 5 6
for v in q5: if v.isupper(): continue else: print(v, end=' ') print()
위의 두가기 방식의 출력값은
1 2
b c e h b c e h
7. 아래 리스트 항목 중에서 소문자는 대문자로 대문자는 소문자로 출력하세요.
재밌는 문제였다. 위의 방법을 그대로 응용하면 되는 문제라 풀면서도 재미있었다 저 출력값들을 한 문장으로 나타내려면 어떻게하면 좋을까? if문 끝난 값들을 temp에 넣고 end()로 한 문장에 넣으면 될 것 같다 나중에 실습해봐야지
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
q6 = ["A", "b", "c", "D", "e", "F", "G", "h"]
for v in q6: if v.isupper(): print(v.lower()) elif v.islower(): print(v.upper()) print()
# 출력값은 a B C d E f g H
그리고 아래 내용들을 학습했다. 정의에 관한 내용이라 블로깅할 부분이 없었지만 강의가 구체적으로 들어가면 자세히 블로깅 할 예정이다
while문은 아래와 같이 나타낼수있다 while문과 for문이 자유자재로 바꿔 생각할 수 있어야 코딩 초짜를 뗄 수있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
v1 =1 while v1 < 11: print("vi is :", v1) v1 +=1 # 출력값은 vi is : 1 vi is : 2 vi is : 3 vi is : 4 vi is : 5 vi is : 6 vi is : 7 vi is : 8 vi is : 9 vi is : 10
이걸 for 문으로 바꾼다면 어떻게 될까?
1 2 3 4 5 6 7 8 9 10 11 12
for v2 in range(1, 11): print("v2 is : ", v2) v2 is : 1 v2 is : 2 v2 is : 3 v2 is : 4 v2 is : 5 v2 is : 6 v2 is : 7 v2 is : 8 v2 is : 9 v2 is : 10
my_info = { 'name' : 'kim', 'city' : 'seoul', 'age' : 77 } # 키를 가져오는 두가지 방법 :기본값과 keys() print('기본값은 키가져오기') for key in my_info: print(key)
for key in my_info.keys(): print(key) # 값 print('값가져오기') for key in my_info.values(): print(key) # 키와 값 둘 다 print('키와 값 둘 다 가져오기') for k, v in my_info.items(): print(k, v)
# 출력값은 기본값은 키 name city age name city age 기본값은 값 kim seoul 77 기본값은 키와 벨류 둘다 name kim city seoul age 77
예제 4 : 대문자는 소문자로, 소문자는 대문자로 바꾸시오
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
name = 'GoodbYe'
for n in name: if n.isupper(): print(n.lower()) else: print(n.upper())
# 출력값은 g O O D B y E
4. break
정말 중요한 break! 사소하지만 효율을 올려준다
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
numbers = [14,3,4,7,10,33,24,17]
for num in numbers: if num == 33: print('찾았다', num) else: print('못찾았다')
# 출력값은 못찾았다 못찾았다 못찾았다 못찾았다 못찾았다 찾았다 33 못찾았다 못찾았다
위의 코드로 하면 원하는 값을 찾은 뒤에 2번 더 실행되는 것을 볼 수 있다. 효율이 떨어지므로 break걸어주면 좋다
1 2 3 4 5 6 7 8 9 10 11 12 13 14
for num in numbers: if num == 33: print('찾았다', num) break else: print('못찾았다')
# 출력값은 못찾았다 못찾았다 못찾았다 못찾았다 못찾았다 찾았다 33
5. for - else 구문
흥미롭게도 python에는 for문에도 else가 있다 (중요) 반복문이 정상적으로 수행 된 경우 else 블럭 수행 블럭안에 break가 들어간 경우 반복문 전체가 실행되지않기에 for-else문이 출력되지않는다
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
for num in numbers: if num == 33: print('찾았다', num) else: print('못찾았다') else: print('반복문끄읕')
이때까지 배운 데이터 타입과 관련하여 16문제정도를 풀어보았다. 다양한 방법으로 풀어보고 출력값이 일치하는 거 보니 참 뿌듯했다. 이런 간단한 사항들을 자유자재로 다룰 수 있어야 나중에 프로젝트를 호율적으로 진행할 수 있을 것임에 틀림없다. 간단하다고 약보지말자. 16가지 문제 중 기억해야할 것들을 위주로 블로깅을 해보려고 한다
1. 문자열 “30” 을 각각 정수형, 실수형, 복소수형, 문자형으로 변환해보세요.
이건 형변환문제이고 아주 쉽지만 중요하다 참고로 문자형은 이미 “30” 문자이기때문에 그대로 적어도 되고 str()을 사용해서 만들어도 된다.
다른 데이터들은 익숙한데 위의 데이터타입들은 생소해서 꼼꼼하게 인강을 들었다. 이러한 데이터들만 잘 활용해도 파이썬을 제대로 사용할 수 있을 것만 같다 신기한게 다음 인강이 test인강이었다. 답을 어디 제출하는 것은 아니지만 숙제개념으로 먼저 풀어본 뒤 인강을 들으면 진짜 학원다니는 느낌(?)을 낼 수 있다 ㅋㅋㅋㅋㅋ
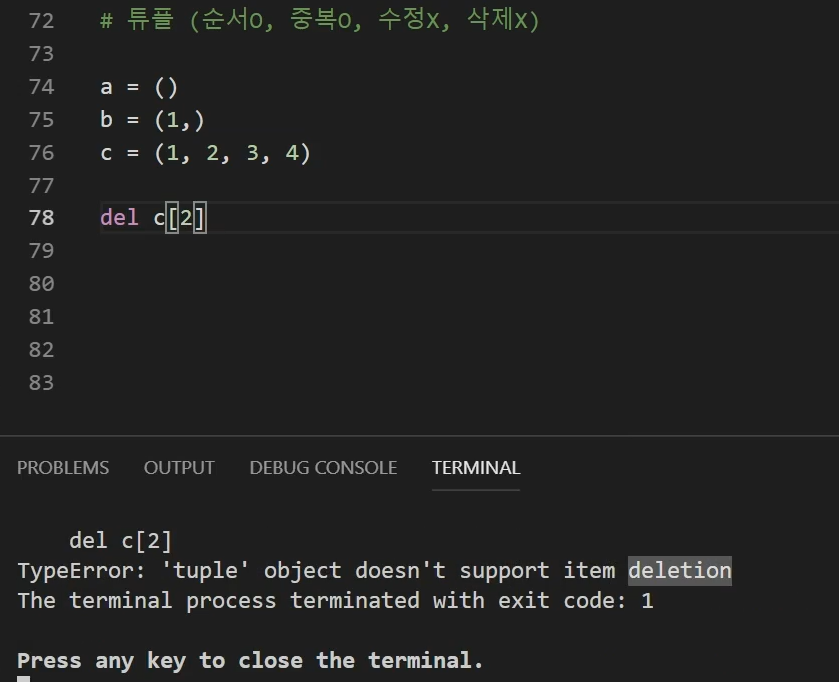
1. 리스트
리스트는 아래 4가지가 다 가능한 매우 유연한 데이터타입이다.
순서O
중복O
수정O
삭제O
1-1 리스트의 선언
선언은 쉽다
1 2 3 4 5 6 7 8
a = [1,2,3,4,5] b = list('a') c = [1,2,'Apple', ['Pink', 'Red']] d = list(1)
print(a.keys()) print(list(a.keys())) # 정말 자주 사용함. 중요해! for반복문할때 temp에 넣어서 자주 사용 temp = list(a.keys()) print(temp[1:3]) print(a.values()) # 대량의 데이터처리가 매우 쉬움 print(a.items())






![[OS/WINDOW]배포후 서버재시작에 batch와 윈도우 스케줄러 활용하기](https://cdn.pixabay.com/photo/2012/03/04/00/50/board-22098_960_720.jpg)
![[블로그]헥소테마에서 댓글기능 facebook에서 utterances로 변경하기](https://miro.medium.com/max/1600/1*aOv6h3h_v9PQWa03zGACnw.png)