![[SQLD] 테이블 분할](/img/SQL.png)
[SQLD] 테이블 분할
SQL을 더 잘 다루고싶어서 공부하다가 하는 김에 결과가 남는 자격증을 도전하게되었다.
테이블 반정규화 과정에는 3가지가 있다.
🏷️ 테이블 반정규화
- 테이블 병합: 1:1관계, 1:M관계, 슈퍼/서브타입
- 테이블 분할: 수직분할, 수평분할
- 테이블 추가: 중복, 통계, 이력
이 중 테이블 분할에 대해 궁금해져 자세히 알아보았다.
테이블은 합치는 것보다 나누는 것이 더 어렵다. 사실 기존 테이블을 바꾼다는 것 자체가 큰 위험이 따른다.
이렇게 위험한 테이블 반정규화를 왜 하는걸까?
반정규화는 시스템 성능향상과 개바로가 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 기법이다. 즉, 장기적으로 봤을 때 기존 시스템보다 개선효과가 클때 반정규화를 한다.
- 테이블 컬럼 수 많을수록 -> I/O(Input/Output) 부하 생김
- 테이블 Row 수 많을수록 -> Index 부하 생김
따라서, 컬럼 또는 로우 기준으로 수직 또는 수평으로 테이블 분리를 통한 성능 개선을 검토한다.
그럼 이제 수직분할과 수평분할을 알아보자.
🏷️ 수직분할
- 정의: 컬럼 기준으로 테이블 분리
- 분리이유
- 만약 한 테이블에 너무 많은 컬럼이 존재한다면 디스크의 여러 블록에 데이터가 저장되어 디스크I/O성능 저하가 일어난다.
- 왜 디스크의 여러 블록에 데이터가 저장될까?
- 로우체이닝과 로우 마이그레이션이 많아지기때문! 로우체이닝과 로우마이그레이션이 많아지면 디스크I/O 성능저하가 나타난다.
- Row Chaining: 길이가 너무 길어 하나의 블록에 저장되지 못하고 다수의 블록에 나눠 저장
- Row Migration: 수정된 데이터를 해당 데이터 블록에 저장하지 못하고 다른 블록 빈 공간에 저장
- 분리기준
- 조회 조건에 맞게 이용되는 컬럼들을 그룹화하여 분리

🏷️ 수평분할
- 정의: Row 기준으로 테이블 분리
- 분리이유
- 대량의 데이터가 하나의 테이블에 있으면 인덱스 정보 생성시 부하가 터진다.
- 집중 발생되는 트랙잰션 해소를 통한 성능 향상
- 왜 인덱시 정보 생성시 부하가 커질까?
- 인덱스 깊이(Depth)가 깊어지면 찾아가는데 해당 depth까지 시간이 오래 걸림
- 인덱스 크기가 커질수록 더 많은 성능 저하
- 분리기준
- 논리적으로 같은 테이블이지만 물리적으로 나누는 파티션 방법 이용

수평분할시 분리기준으로 파티션 방법이 있다. 파티션 방법이 구체적으로 뭘까?
파티셔닝 종류
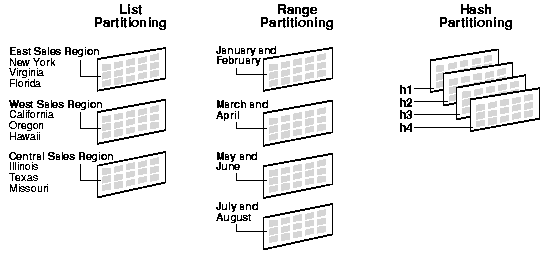
| 파티셔닝명 | 분리기준 | 예시 |
|---|---|---|
| List | 사용자가 지정한 값으로 분리(불연속적, 보통 핵심적인 코드값) | 판매데이터를 지역별로 |
| Range | 주로 날짜 또는 숫자값 기준으로 분리 | 판매데이터를 분기별로 |
| Hash | 파티션 키 값에 해시 함수를 적용하여 지정된 Hash조건에 따라 분리 | 고객번호, 주문일련번호 등 |
| Composite | Range나 List 파티션 내 다른 서브파티션 | Range + List 또는 List + Hash |
![[OS/WINDOW]배포후 서버재시작에 batch와 윈도우 스케줄러 활용하기](https://cdn.pixabay.com/photo/2012/03/04/00/50/board-22098_960_720.jpg)
![[블로그]헥소테마에서 댓글기능 facebook에서 utterances로 변경하기](https://miro.medium.com/max/1600/1*aOv6h3h_v9PQWa03zGACnw.png)