[패스트캠퍼스python] 데이터타입(리스트, 튜플, 딕셔너리, 셋)
데이터타입(리스트, 튜플, 딕셔너리, 셋)
다른 데이터들은 익숙한데 위의 데이터타입들은 생소해서 꼼꼼하게 인강을 들었다.
이러한 데이터들만 잘 활용해도 파이썬을 제대로 사용할 수 있을 것만 같다
신기한게 다음 인강이 test인강이었다. 답을 어디 제출하는 것은 아니지만 숙제개념으로 먼저 풀어본 뒤 인강을 들으면 진짜 학원다니는 느낌(?)을 낼 수 있다 ㅋㅋㅋㅋㅋ
1. 리스트
리스트는 아래 4가지가 다 가능한 매우 유연한 데이터타입이다.
- 순서O
- 중복O
- 수정O
- 삭제O
1-1 리스트의 선언
선언은 쉽다
1 | a = [1,2,3,4,5] |
출력값으로는
1 | [1, 2, 3, 4, 5] |
d = list(‘a’)는 출력이 가능하나 list(1)은 출력이 불가능했다.
1-2 리스트의 인덱싱
위의 선언을 그대로 아래코드를 입력했다
1 | print(c[0]) |
그 출력값은 아래와 같다.
특히 -인덱스에서 출력되는 값들이 조금 헷갈린다
실습을 많이해서 실수하지 않도록 해야겠다.
1 | 1 |
1-3 리스트의 슬라이싱
선언한 c에서 1부터 사과까지의 값만 가지고 오고싶다면 슬라이싱을 하면 된다.
1 | c = [1,2,'Apple', ['Pink', 'Red']] |
출력값
1 | [1, 2, 'Apple'] |
1-4 리스트의 연산
곱하기 연산이 신기했다
1 | a = [1,2] |
출력값은
1 | [1,2,1,2,1,2] |
1-5 리스트의 수정 및 삭제
리스트는 수정 및 삭제가 간편했다.
1 | c[0] = 77 |
출력값
1 | [77, 2, 'Apple', ['Pink', 'Red']] |
1-6 리스트 함수
함수는 재미있는 내용이 꽤 많았다
- append(a)와 insert(a,b), extend(c)의 차이점
- append(a)는 배열 맨 뒤에 a값을 넣음
- insert(a,b)는 a번째 인덱스에 b값을 넣음
- list.extend(a)는 a가 배열인 경우 배열 통채로 list에 삽입되지만 list.extend(a)는 a의 원소들이 list에 삽입됨
차이점은 아래 코드를 보면 명확히 나타난다
1 | y = [5,2,3,1,4] |
출력값은
1 | [5, 2, 3, 1, 4] |
append는 배열 통채로 추가되는 것을 확인할 수 있다.
sort()와 reverse()는 서로 반대!
- sort()는 순서대로정렬, 오름차순정렬
- reverse()는 역순정렬, 내림차순정렬
del, remove(), pop()은 셋 다 삭제하는 기능이다!
- del는 인덱스로 삭제 가능
- remove(a)는 인덱스의 값이 지워지는게 아니라 a라는 값을 찾아서 삭제해줌
- pop() 맨 마지막 값을 꺼냄, 참고로 pop()과 push())를 LIFO(Last in first out)구조를 가진 스택(Stack)이라고 부른다
1 | y.remove(7) |
출력값은
1 | [1, 2, 3, 4, 5, 6] |
2. 튜플
언뜻보면 리스트와 다름없는 튜플은 왜 있는걸까?
수정이나 삭제되면 안되는 중요 데이터를 다룰때 튜플에 저장사용하면 좋기 때문이다
리스트와 중복되는 부분이 많아 내게 필요한 부분만 정리해보았다
- 순서O
- 중복O
- 수정x
- 삭제x
1 | d = (10, 20, 30, ('a', 'b', 'c')) |
출력값은
1 | (30, ('a', 'b', 'c')) |
마지막 출력값에 ,가 찍히는 건 튜플의 특성이다.
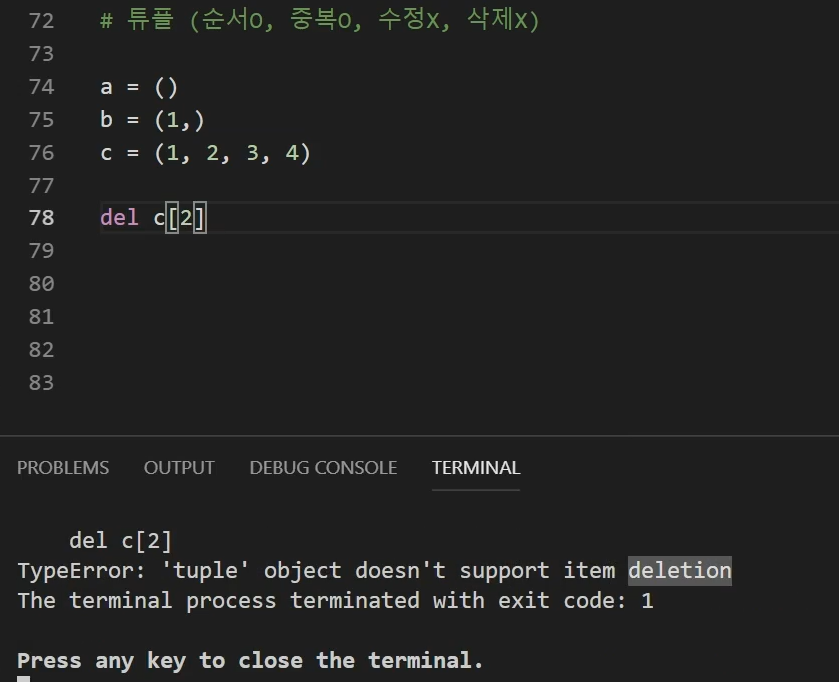
튜플은 수정과 삭제가 안되기 때문에 위의 이미지처럼 del로 삭제를 시도한 경우 터미널에 TypeError코드가 생기며 deletion을 support하지 않는다고 알려준다.
3. 딕셔너리
dictionary 는 key, value, items를 구분할 줄 알아아한다.
딕셔너리를 배우면서 이렇게 데이터를 효율적으로 다룰 수 있단 말이야? 하며 크게 놀랐다.
왜 파이썬이 데이터베이스에 많이 사용되는 언어인지 이해가 갔다.
- 순서x
- 중복x
- 수정o
- 삭제o
3-1 딕셔너리의 선언
1 | a = {'name' : 'kim', 'Mobile':'02-3196-777'} |
3-2 딕셔너리의 출력
딕셔너리 출력시 그냥 출력하는 것보다 get()을 이용하는 걸 추천한다.
get()을 이용해서 key를 찾으면, None을 통해 key유무를 확실히 확인할 수 있어 유용하다
1 | print(a['name']) |
둘 다 동일한 출력값을 가진다.
1 | kim |
3-3 딕셔너리의 추가
1 | a['address'] = 'Seoul' |
3-4 keys, values, items(keys와 values 합친거)
형변환 필수!
1 | print(a.keys()) |
출력값은
1 | dict_keys(['name', 'Mobile', 'address']) |
3-5 ( in )은 keys 유무확인만 가능할뿐 value유무확인은 안됨
1 | print('name' in a) |
출력값은
1 | True |
4.집합(Sets)
셋의 특징은 아래와 같다.
셋을 통해 파이썬이 빅데이터처리에 유용하다는 것을 느꼈다.
- 순서x
- 중복x
1 | z = set([1,2,7]) |
출력값은
1 | {1, 2, 3, 4, 5, 6} |
sets은 중복을 허용하지않기때문에 알아서 중복제거해준다.
4-1 교집합
1 | print(z.intersection(y)) |
동일한 출력값을 가진다
1 | {1, 2} |
4-2 합집합
1 | print(z | y) |
동일한 출력값을 가진다
1 | {1, 2, 3, 4, 5, 6, 7} |
4-3 차집합
1 | print(z - y) |
출력값은
1 | {7} |
위에서 배웠던 데이터타입을 가지고 형변환을 하면 아래 이미지와 같이 출력된다
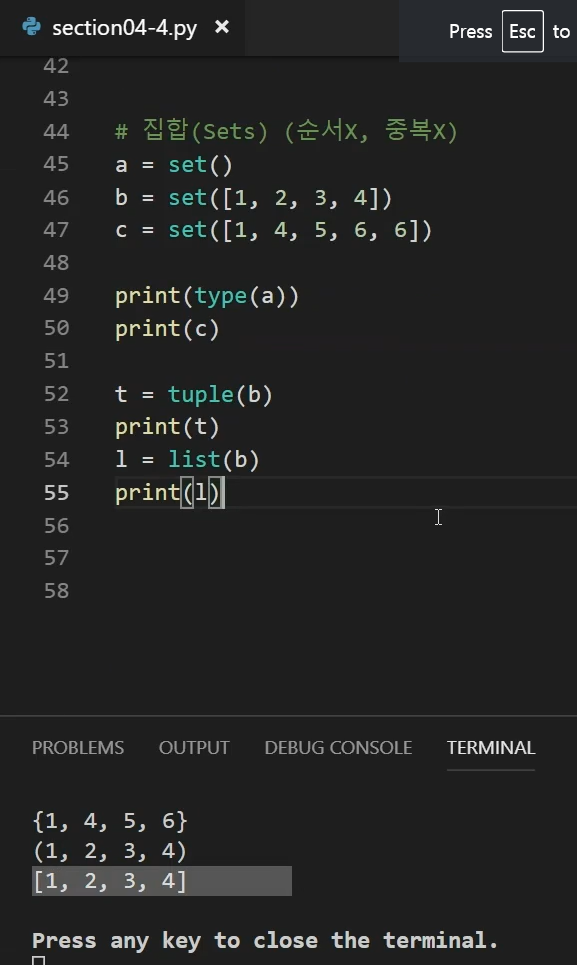
괄호의 모형도 다르고 type도 다르다.
드디어 자료형에 대해 개략적으로 공부 완료했다
실습을 통해 내것으로 빨리 만들어보는 시간을 가졌으면 좋겠다.
![[OS/WINDOW]배포후 서버재시작에 batch와 윈도우 스케줄러 활용하기](https://cdn.pixabay.com/photo/2012/03/04/00/50/board-22098_960_720.jpg)
![[블로그]헥소테마에서 댓글기능 facebook에서 utterances로 변경하기](https://miro.medium.com/max/1600/1*aOv6h3h_v9PQWa03zGACnw.png)